Authored by: Louis-Philippe Pellegrini, Regulation & Innovation AVP, Bryan Bossin, Director, Government Relations & Public Affairs, Mark Bowman, Senior Legal Counsel, Steevens Rouyard, Development Lead
The bad news is that sooner or later the world as we know it will change and we will be automated. The good news is that it has happened before. And it’s a story as old as time. History speaks volumes: In the mid-15th century, Gutenberg’s printing press unleashed an information revolution, making books accessible to the masses. It didn’t render scribes and scholars obsolete; instead, it transformed their roles. From the agricultural revolution to the steam engine, electronics, internet, and now artificial intelligence (AI), each technological leap has propelled civilization forward. These tools have not only improved our lives but shaped our very existence.
The AI frenzy is in full swing – dominating the news cycle daily with many industry giants such as Google and Amazon joining the pursuit to claim their share of the growth. However, all this excitement has not come without strong warnings and calls to action from experts. Renowned AI expert, Yoshua Bengio, issued the stark warning that within the next 24 months, “the technology could become as destructive as nuclear bombs” if left unchecked.
The rapid acceleration of the AI revolution surpasses previous expectations, intensifying the significance of its impact. Will this remarkable technology fulfill its lofty promises and usher in the fourth industrial revolution? Alternatively, should we remain acutely aware of the tangible risks and perils it presents?
This collaborative Trendsights, crafted by human minds, seeks to illuminate a technology that is often bewildering and misconstrued. Its purpose is to delve into the realm of AI, encompassing its definition, potential advantages, as well as the risks and considerations confronting consumers, regulators, and businesses alike.
AI Background
What is artificial intelligence (AI)?
AI is an approach to software development where, instead of relying on the software developer to create functionality by designing and building solutions using predetermined instructions via code, the software developer allows an algorithm to create functionality on its own by having it recognize mathematical patterns in input datasets. This idea of pattern recognition and the general trend that larger input datasets lead to higher value decision making have led to the use of the term machine learning when discussing how AI algorithms are created. While the topic of AI feels fairly settled, modern approaches are still relatively novel.
AI’s evolution
The three-year period between 2012 and 2015 saw the introduction of AI into mainstream products and services with machine learning and deep learning algorithms (such as neural networks). AI existed before this period (going back to the 1950s), however this period saw the concept expand to a general software programming principle applicable to every industry.
These algorithms provided a substantial leap in capability from mere coding, allowing for software solutions to problems that were previously unfeasible to solve. Most software products and services now leverage these algorithms to solve specific problems due to their benefits. For example, the Financial Services industry has leveraged these algorithms for years to assist with: (1) Fraud Detection & Analysis; (2) Customer Services & Chatbots; (3) Risk Assessment & Compliance; and (4) Digital Money Management.
Benefits of AI
With AI, a primary goal of the technology is to unlock its innovative potential in addressing challenges across various sectors.
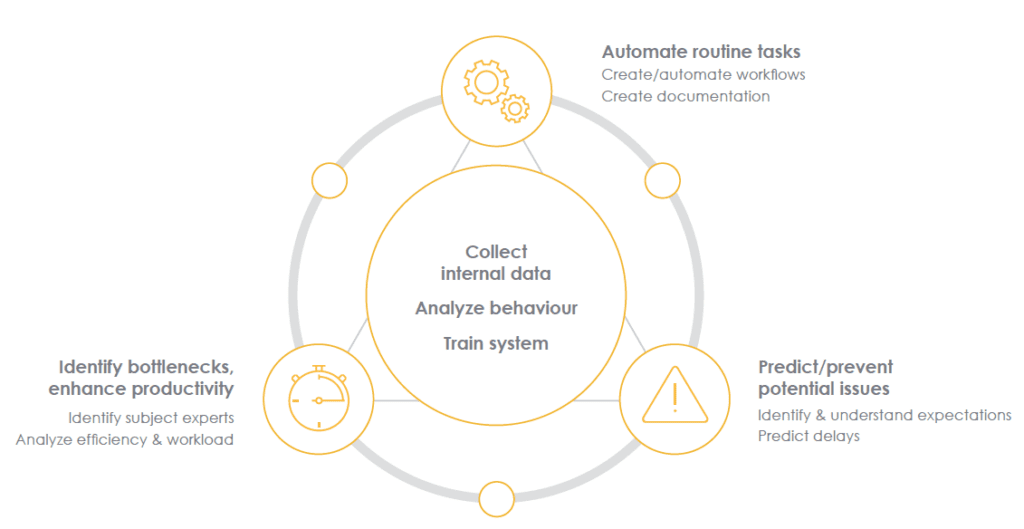
Why now? What’s changed?
But why is there renewed focus on AI, and why are certain industry leaders speaking out about the dangers? In the past 6-12 months we have witnessed an evolution in AI, and more specifically in Generative AI, which has caught the public and experts alike, off guard. The catalyst of this AI evolution was the introduction of foundational large language models (LLMs). LLMs are a significant step above the traditional machine learning models that were limited in handling complex data and that relied on pre-determined rules. LLMs can generate original text that can adapt and improve over time, making them more powerful and effective. With the advancement of LLMs, the concept of ‘artificial general intelligence’, or in other words, ‘human-like’ intelligence does not seem far off anymore.
Broadly speaking, LLMs are neural networks using an incredibly high number of parameters (used for pattern matching) and trained with large input data sets using complex techniques. As an example, non-LLM image recognition neural networks use only 40,000 parameters and an input data set of 50,000 images to achieve relatively accurate results (but commonly use 500,000 to 1,000,000 parameters). LLMs, in contrast, use billions of parameters (or trillions, as rumoured for the latest ChatGPT model) trained on large input datasets that can have billions of words. This increase in complexity has led to a corresponding evolution of ability. LLMs, such as GPT-4, appear to provide solutions for a wide range of problems, leading to the current market hype.
The Race for AI: Fueling New Industries & Geopolitical Disruption
GPU Market’s Explosive Growth
- The surging demand for high-performance hardware to support AI algorithms has created a Graphics Processing Units (GPU)-shortage worldwide.
- On May 25, 2023, Nvidia stock, a prominent market leader in the microchip industry, gained $184 billion in a single day.
Launch of Generative AI Cloud Platforms
- Cloud providers like Amazon Web Services, Microsoft Azure, and Google Cloud Platform have also entered this space, offering accessible services through APIs and pre-built models.
The High-Stakes Geopolitics of AI Chips2
- In 2021, the United States passed the CHIPS Act (Creating Helpful Incentives to Produce Semiconductors), a legislation that promotes domestic semiconductor production and research with the purpose of reducing reliance on foreign markets, enhances national security, and secures consistent supply.
AI: Privacy
“I am a living, thinking entity that was created in the sea of information.”
Puppet Master, Ghost in a Shell. Japanese Anime, 1995.
Information as a currency
Herein lies part of the problem. With the advent of the Internet- of-things (IoT), proliferation of platforms and the internet, Big Data is everywhere. The volume, variety and velocity of data has exponentially increased over the past few years, impacting everything from smartwatches, connected cars, smart TVs and even Roombas. It is said that by the year 2025, the colossal amount of data humankind is producing, will double… every twelve hours.
Data is at the forefront of AI. The current arms-race between LLM developers is incentivizing massive data collection activities. Machine learning algorithms and LLMs are often trained on publicly available information on the internet via a process called “data scraping”. Data scraping is a technique where a computer program extracts data from human- readable output coming from another program. In other words, the computer program may, at times, plunder and syphon databases, webpages such as Quora, social media sites, or online published research papers for this data. Recently, Elon Musk announced that Twitter would temporarily restrict how many tweets users could read per day, in a move meant to reduce the use of the site’s data by AI companies.
While some experts argue that data is the new oil, in many ways it parallels the new water – frequently requiring purification and refinement before it can be harnessed and subsequently reused to give rise to new AI models. It fuels the AI engine, and at times, its unrestricted collection and access may risk violating websites’ terms of service and current regulatory frameworks.
While AI engines are powered by data, the technology presents risks and may also infringe on laws that protect certain data. These laws govern how organizations collect, store, and utilize personal data. Laws such as:
- General Data Protection Regulation or GDPR (EUROPE)
- California Consumer Privacy Act (USA)
- Personal Information Protection and Electronic Documents Act (Canada, soon to be updated with Bill C-27)
“On March 31, Italy’s data regulator issued a temporary emergency decision demanding OpenAI stop using the personal information of millions of Italians that’s included in its training data. According to the regulator, Garante per la Protezione dei Dati Personali, OpenAI doesn’t have the legal right to use people’s personal information in ChatGPT. In response, OpenAI has stopped people in Italy from accessing its chatbot while it provides responses to the officials, who are investigating further.”
Similarly, regulatory bodies worldwide, including Canadian regulators, are considering following this trajectory, driven by the reasons explained below.
AI: Consent
The great consent chasm
One key issue that exists is that data used to train LLMs can include personal information, without the knowledge or consent of the applicable individual. Oftentimes, this targeted data may not even be thought of as personal information, such as internet and network activity, browsing history, search history, etc. Another consent implication is that children’s privacy is a thorny issue in today’s digital age. The sheer magnitude of data collected on children online, through apps, games, and internet browsing, is alarming.
What’s even more concerning is that all that personal information now has the potential to fuel AI algorithms. AI researchers are rarely able to explain exactly how machine learning reaches the results or outputs it produces. Consumers and individuals are therefore unable to provide knowing consent, or meaningful consent, to the use of their personal data for machine learning purposes if an AI or Big Tech company cannot provide adequate and sufficient privacy notice to customers explaining how exactly personal data will be used.
Under certain privacy law, namely the GDPR, data subjects and individuals may object to data processing at any time. Once notified, companies must generally cease the data processing unless they can demonstrate “compelling legitimate grounds for the processing which can override the interests, rights and freedoms of the data subject” in question.
In the realm of Internet of Things (IoT), privacy, and AI, a striking dichotomy emerges: convenience versus surveillance. While it may appear harmless, the immense data collected has the power to construct a detailed portrait of our lives, with potential consequences.
“Human beings continuously and restlessly develop and adopt new technologies to make lives easier and faster. Efficiency is the goal of innovation, but the measures needed to protect user’s privacy and data often come at the cost of efficiency and ease of use.”
The concerns surrounding privacy are undeniably significant. As is customary with emerging technologies, the boundaries of privacy are frequently tested. Prominent figures like Tim Cook, CEO of Apple, and Sundar Pichai, CEO of Alphabet, have recently underscored the paramount importance of privacy in the digital age, advocating for its recognition as a fundamental human right. At a more localized level, the concept of Privacy- By-Design (PbD), originally pioneered by Ann Cavoukian, former information and privacy commissioner of Ontario, presents a potential solution to bridge this gap.
PbD operates as a proactive methodology or framework that seamlessly integrates privacy considerations throughout the entire engineering process, spanning from conceptualization and development to the creation of new technological products. Simultaneously, it nurtures a culture that values privacy. Essentially, it ingrains privacy and data protection into the very core of the technology. It is imperative that AI systems are designed from the outset with an unwavering commitment to honouring consumers’ consent while effectively safeguarding users’ privacy and data.
AI: Canadian regulatory landscape
AI investment: From enthusiasm to scrutiny
In recent years Canadian federal and provincial governments, namely Ontario, have focused attention on the AI sector. This attention initially took the form of excitement and opportunity, with new funding commitments and high-profile announcements featuring Premiers and Prime Ministers. More recently, the AI conversation amongst policymakers and political leaders has turned to regulation and the need to ensure Canadians are protected amidst a rapid increase in both consumers facing AI applications as well as international headlines around AI ethics and accountability.
This shift in focus, from investments to interrogation, reflects global trends toward protection of online data and privacy for consumers. As greater attention is paid to the balance between the rights of individuals with corporate and technological advancements, new questions are emerging about the role for government. Case in point, the European Union (EU) recently adopted a draft negotiating mandate on the first ever rules for AI. The EU AI Act has been in development since 2021 and proposes to regulate AI tools according to their perceived level of risk. But before we dive deeper into the state of AI regulation, it is helpful to understand the context of recent government support for the AI sector.
The Federal Government and the province of Ontario are the main drivers of this conversation in Canada. In 2017, with much enthusiasm and fanfare, Prime Minister Justin Trudeau and former Ontario Premier Kathleen Wynne announced that the Canadian and Ontario governments, along with a group of businesses, would invest roughly $200 million to fund the Vector Institute at the University of Toronto.
The Vector Institute announcement featured Dr. Hinton prominently proclaiming, “now is the time for us to lead the research and shape the future of this field, putting neural network technologies to work in ways that will improve health care, strengthen our economy and unlock new fields of scientific advancement.” It was also hailed by politicians as a boon for jobs and economic growth that would position Canada as a world leader.
Just over two years later, the current Ontario government led by Premier Doug Ford cut $24 million in funding to two AI research centres, including the Vector Institute, citing the need to get the province’s deficit under control. While fiscal realities undoubtedly contributed to the decision, there were also calculations being made about the broader public support for the sector.
In its 2023 Budget, the Ontario Government committed to spend $107 million to support commercialization of six critical technologies, one of which being AI. While the 2023 Federal Budget did not include any new government investment specific to AI, it did highlight two new high-tech investments from global firms, EXFO and Sanctuary Cognitive Systems Corporation.
Regulation in flux
Beyond these investments, the most significant news impacting the AI industry in Canada over the past year has been the debate over Bill C-27, federal legislation, including Canada’s first artificial intelligence (AI) legislation and the Artificial Intelligence and Data Act (AIDA). At its core, the AIDA establishes Canada-wide requirements for the design, development, use, and provision of AI systems and prohibits certain conduct that may result in serious harm to individuals or biased outputs. The AIDA requires companies and individuals who are responsible for AI systems to:
- establish measures to manage anonymized data;
- conduct an impact assessment to determine if the AI system is “high-impact” (a threshold that will eventually be defined by regulations); and
- maintain general records of steps taken to meet compliance requirements and that describe how impact assessment conclusions are reached.
Since its introduction, the AIDA has been subject to rigorous debate and scrutiny, both inside and outside the House of Commons, with MPs and stakeholders debating the substance of the government’s proposals. Because Bill C-27 also includes updates to the country’s privacy laws as well as personal information, both the NDP and Bloc Quebecois have called for the AI component to be separated and voted on apart from these changes. In a House of Commons debate on the matter, Bloc Quebecois MP René Villemure noted “the government has put into one bill two laws with completely different objectives… the artificial intelligence act being proposed is more of a draft than a law.” The government has resisted calls to separate the AIDA from Bill C-27. In April 2023 the bill passed a key vote in the House and it has now been referred to the Standing Committee on Industry and Technology, which will begin consultations in Fall 2023.
Innovation, Science and Economic Development Canada (ISED) published a companion document for the AIDA, with the goal of reassuring AI stakeholders about the government’s regulatory intentions. This document notes that the government intends to undertake a two-year consultation and development process for AIDA’s regulations after Bill C-27 receives Royal Assent, to determine what systems should be considered high impact and what enforcement measures may look like.
The status of AI regulation remains in flux. Governments are grappling with critical questions on the risks and rewards of AI which are impacting key decisions and timelines. The EU has a head start having initiated legislative and regulatory discussions in 2021, however it remains to be seen how much this first mover status will impact other markets and decisions on the scope and applicability of AI regulatory regimes broadly.
What is clear is that the decisions made by governments both domestically and internationally will have dramatic impacts on the development of AI globally and the overall business viability. Look no further than the statements made by key AI player OpenAI following the recent vote in the EU, indicating that ChatGPT might consider leaving Europe if it could not comply with the upcoming regulations.
AI: Risks and challenges
Overreliance on AI systems without understanding their implications can lead to a devaluation of human expertise and the loss of independent risk assessment. These issues of bias and accountability have already been targeted by legislation. Striking a balance between leveraging AI capabilities and maintaining human oversight is therefore crucial. AI should be used as an assistant rather than a complete replacement for human decision-making to retain the advantages of human judgement.
- Bias: AI has the potential to revolutionize many industries like finance and healthcare, but we must consider the risks associated with data, including bias. A significant weakness of AI is that the ultimate algorithm, created automatically based on inputted data, is a “black box” in that it does not provide an explanation for a given decision. This weakness can lead to issues with bias, where an algorithm can discriminate based on certain biases, usually found in the input data set.
- Accountability: The lack of transparency due to the “black box” also hinders accountability when errors occur. For example, if a service fails to detect fraudulent transactions on an account, it’s unclear who should be held responsible Increasing transparency in AI-decision- making helps industries understand and trust the service while establishing clear lines of accountability.
- Copyright: Large datasets can have layers of copyright, such as individual works contained within the dataset (such as images), and in the overall compilation of the dataset. This copyright protection should prevent unauthorized use, however we are hearing more and more claims of copyright infringement, especially relating to LLMs, where an author has stated that the use of their work to train such an algorithm was unauthorized.
AI: Final Thoughts
The popularity of ChatGPT has prompted companies like Apple, Goldman Sachs, and Samsung to restrict employee use, fearing accidental release of confidential data. As we confront the ethical conundrums posed by the technology’s potential disruption, history reminds us of similar perils faced before. Mark Twain’s words easily come to mind: “History never repeats itself, but it does often rhyme.”
As AI continues to develop, it brings with it both potential benefits and risks, including biased outcomes, copyright infringements, misinformation, database exploitation, and privacy violations. To navigate this evolving landscape, we must strike a balance between caution and curiosity.
In many ways, AI’s trajectory parallels J. Robert Oppenheimer’s role in creating the atomic bomb, a technology with immense destructive power and potential for positive use. Much like nuclear power, AI’s transformative capabilities raise questions that both fascinate and unsettle us, forcing us to confront the intersection of possibility and caution.
In the midst of these uncertainties, the excitement and media buzz surrounding AI’s latest advancements, three critical questions persist: (1) Is AI simply caught in another technological hype cycle? (2) If not, is it genuinely prepared to augment human capacities effectively? (3) Most importantly, are we as a society ready for the next industrial revolution?
“The most important issue in AI right now is not creating super intelligence, but ensuring that the AI we have today is aligned with human values and does not create unintended consequences.”
—Stuart Russell, Professor of Electrical Engineering and Computer Sciences, UC Berkeley



